Exploración y diagnóstico de la colección
La evaluación con fines de exploración y diagnóstico consiste en realizar una descripción de la colección que tiene la biblioteca. Supone determinar su composición y tamaño en base a los criterios determinados por la propia biblioteca y establecidos en la política. En caso de no disponer de una política escrita es posible guiarse por los criterios que sobre la colección proponen las recomendaciones internacionales. Atento a ello, y sólo con fines ilustrativos proponemos una guía de los aspectos que suelen ser considerados en esta descripción de la colección
Nivel de cobertura y grado de exhaustividad
La evaluación de este aspecto consiste en realizar una descripción del alcance que la colección tiene en relación con el tipo de biblioteca y los principales grupos de usuarios a los que dirige sus servicios.
Esta descripción podría ser del tipo:
“Por el carácter de biblioteca universitaria, la colección de esta biblioteca está orientada prioritariamente a satisfacer las necesidades informacionales de los estudiantes, los docentes y los investigadores de la institución, y en segundo lugar a las demandas del personal de gestión y administración. Está conformada principalmente por documentos de carácter académico y científico, quedando fuera de su cobertura el material de divulgación y de recreación.”
Un aspecto a atender en esta delimitación de la cobertura y grado de exhaustividad de la colección es la existencia de subcolecciones especiales con valor histórico, bibliofílico, cultural, etc. que forman parte del patrimonio bibliográfico de la institución, pero que no responden directamente a los fines académicos y científicos de la comunidad actual de usuarios. Estas particularidades, propias de cada biblioteca, deberían reflejarse en la descripción del nivel de cobertura y grado de exhaustividad de la colección, para facilitar luego una correcta segmentación de la colección que sea objeto de cualquier tipo de evaluación.
Tamaño y crecimiento de la colección
El tamaño de la colección es la cantidad total de títulos y volúmenes de documentos que conforman el fondo bibliográfico de la biblioteca. En términos relativos se refiere al ratio entre el número de títulos o volúmenes y la cantidad de titulaciones o el número de usuarios. El crecimiento de la colección es una medida que permite conocer su dinámica, y principalmente en qué medida crece respecto de las nuevas titulaciones o la cantidad de usuarios.
Como valores de referencia del tamaño y crecimiento de la colección se pueden tener en cuenta las recomendaciones internacionales para monografías, publicaciones periódicas y bases de datos. En nuestro caso hemos considerado las recomendaciones cuantitativas de la Association for College and Research Libraries (ACRL, 1989), de la Red de Bibliotecas Universitarias Españolas Españolas (REBIUN, 1999) y del Consejo de Rectores de Universidades Chilenas (CRUCH, 2003).
Cabe aclarar que si bien la última edición de los estándares de ACRL (ACRL, 2004) reemplaza a las versiones anteriores de 2000 y 1989, las cuales contenían las recomendaciones cuantitativas consignadas en el cuadro que sigue, hemos decidido utilizarlas igualmente debido a que se trata de recomendaciones que se encuentran ampliamente difundidas en el mundo de las bibliotecas universitarias, a tal punto que tanto la Comisión Asesora de Bibliotecas (CABID) del CRUCH como REBIUN, las tomaron como modelo en su momento, y aún no las han modificado, ya que sus versiones de estándares son anteriores a la última versión de ACRL.
Minería de datos
Para la fase de minería de datos de los indicadores incluidos en el cuadro siguiente se recomienda consultar la Guía de referencia de indicadores para la evaluación de colecciones.
Estructuración de los datos
A partir de los datos relevados y a efectos comparativos podemos estructurar los indicadores en un cuadro como el del siguiente ejemplo:
Minería de información
A partir de estos datos podemos extraer la siguiente información:
- Recursos monográficos mínimos: La COLECCIÓN EVALUADA supera la cantidad de volúmenes que recomiendan los estándares. No obstante, no debe perderse de vista que cantidad no es equivalente a calidad, es decir, contar con un número importante de volúmenes no asegura que la colección de que se dispone sea la más adecuada para la comunidad de usuarios a la que la Biblioteca sirve.
- Recursos monográficos por alumno: La COLECCIÓN EVALUADA está por debajo del valor recomendado por los estándares analizados, mejorando su situación cuando se establece la relación monografía-usuarios reales.
- Recursos monográficos por profesor (exclusiva): En cuanto a este aspecto, la COLECCIÓN EVALUADA presenta un valor que duplica al propuesto por los estándares. Esta situación está dada por la cantidad importante de volúmenes con que cuenta la Biblioteca y el bajo número de profesores de la Facultad que poseen una dedicación exclusiva. En cuanto a usuarios reales, no ha podido establecerse la comparación ya que no se dispone de información suficiente.
- Soporte de la colección monográfica: La COLECCIÓN EVALUADA duplica el porcentaje establecido por el estándar chileno, ya que la mayoría de sus documentos se hallan en soporte impreso. Este dato también deja de manifiesto la escasa oferta de materiales en soportes diversos, tales como los electrónicos, audiovisuales, sonoros y otros, que brinda la biblioteca en estudio.
- Volúmenes monográficos por nueva carrera: Esta información no está disponible para la COLECCIÓN EVALUADA, dado que no hay establecido a nivel institucional un presupuesto para la compra de bibliografía para cada nueva carrera que se cree.
- Título de publicaciones periódicas: La COLECCIÓN EVALUADA coincide con el valor recomendado por el estándar español, aunque se aleja notoriamente de lo recomendado por el estándar chileno.
- Incremento anual: En cuanto a este aspecto, es lamentable la situación de la COLECCIÓN EVALUADA ya que, no sólo no llega al mínimo establecido por los estándares, sino que se encuentra muy por debajo de lo recomendado, manifestando de esta manera el escaso crecimiento anual que posee la colección en relación con la cantidad de miembros de la comunidad académica a la que sirve.
Tipos documentales y soporte
Para cada tipo documental y soporte que conforme la colección de la biblioteca se obtendrá el número y porcentaje de títulos y volúmenes respecto del total de la colección. Realizar esta segmentación es muy importante para otros estudios evaluativos porque, en general, los métodos e indicadores para la evaluación difieren según sean los tipos de documentos y soportes considerados.
Minería de datos
Para determinar el número de títulos por cada tipo documental y soporte se generará a partir del catálogo de la biblioteca un archivo de texto (*.txt) conteniendo el número de registro, el tipo de documento y el soporte. El número de registro es el MFN en bases de datos ISIS. Cada dato en el archivo de texto deberá aparecer separado con un carácter especial, por ejemplo pipe (|).
El archivo de texto adopta la siguiente forma:
000006|Libro|Impreso
000009|Libro|Digital
000010|Libro|Impreso
000011|Libro|Impreso
000012|Libro|Impreso
000013|Revista|Digital
000015|Folleto|Impreso
000017|Folleto|Impreso
000018|Revista|Impreso
000019|Tesis|Impreso
000020|Revista|Impreso
000021|Revista|Impreso
000022|Tesis|Impreso
...
Estructuración de los datos
Abrimos el archivo con una planilla de cálculo y disponemos los datos en tres columnas utilizando la función Texto en columnas. Los datos quedarán dispuestos del siguiente modo:
A partir de estos datos se procederá a realizar los recuentos. Para ello recomendamos utilizar la función de tablas dinámicas de la planilla de cálculo, o funciones como Contar.Si. Los datos pueden recolectarse y estructurarse en una tabla como la del siguiente ejemplo:
Minería de información
A modo ilustrativo incluimos un ejemplo de tabla completa. Los totales de esta tabla representan la cantidad total de títulos y volúmenes de la colección de la biblioteca.
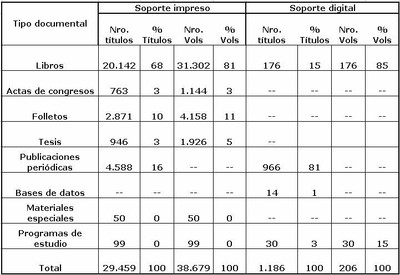
Los datos revelan información sobre la composición de la colección en términos de tipo documental y soporte. La mayoría son libros en soporte impreso (68% de los títulos y 81% de volúmenes). Le siguen las revistas que representan el 16% de la colección impresa, los folletos, las tesis y las actas de congresos. Hay una escasa presencia de recursos en soporte digital.
Idiomas
Esta característica permite determinar cuál es la capacidad idiomática de la colección. Para ello se obtendrá el número y porcentaje de títulos y volúmenes de cada idioma en el que se encuentre el texto de los documentos. Se recomienda realizar los recuentos de manera independiente para cada tipo documental. Por ejemplo, en las siguientes tablas se representan los idiomas de la colección de libros.
Minería de datos
Para determinar el número de títulos y volúmenes por idioma se generará a partir del catálogo de la biblioteca un archivo de texto (*.txt) conteniendo el número de registro, el idioma del texto. El número de registro es el MFN en bases de datos ISIS. Cada dato en el archivo de texto deberá aparecer separado con un carácter especial, por ejemplo pipe (|). Como el idioma puede ser repetible (es decir, hay textos en más de un idioma) el número de registro aparecerá repetido tantas veces como idiomas se hayan ingresado en el registro. Los idiomas en el catálogo de ejemplo están codificados con la norma ISO 639.
El archivo de texto tendrá la siguiente forma:
000006|es
000009|en
000010|en
000010|es
000011|en
000012|es
000013|en
000013|es
000015|es
000015|en
000017|de
000018|es
000019|es
000020|es
000021|es
000022|es
000023|es
000023|en
000024|en
000025|es
000026|de
000027|fr
000028|de
000029|pt
000030|es
000030|en
Estructuración de los datos
Abrimos el archivo con una planilla de cálculo y disponemos los datos en tress columnas utilizando la función Texto en columnas. Los datos quedarán dispuestos del siguiente modo:
A partir de estos datos se procederá a realizar los recuentos. Para ello recomendamos utilizar la función de tablas dinámicas de la planilla de cálculo, o funciones como Contar.Si.
Los datos resultantes de los recuentos pueden compilarse en una tabla como la del siguiente ejemplo:
Minería de información
A modo ilustrativo incluimos un ejemplo de tabla completa que aporta información sobre la capacidad idiomática de la colección (en este caso de la colección de libros impresos de la biblioteca seleccionada).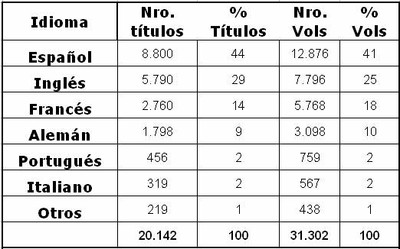
Cobertura temática
Para la descripción temática de la colección cada biblioteca deberá seleccionar el esquema de clasificación a utilizar (CDU, CDD, Encabezamientos de materia, etc.), así como también el nivel de especificidad al que se pretenda llegar. Para una primera aproximación al conocimiento de la composición temática de la colección sugerimos realizar una segmentación por clases generales. En nuestro caso elegimos las clases de CDU (0, 1, 2, 3, etc.) para cada tipo documental. Para cada una de las clases obtuvimos el número y porcentaje de títulos y volúmenes.
Minería de datos
A partir del catálogo de la biblioteca un archivo de texto (*.txt) conteniendo el número de registro y el primer carácter de la clasificación CDU. El número de registro es el MFN en bases de datos ISIS. Cada dato en el archivo de texto deberá aparecer separado con un carácter especial, por ejemplo pipe (|).
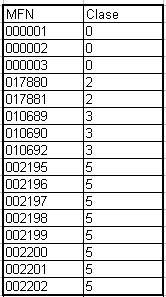
El archivo de texto tendrá la siguiente forma:
000001|0
000002|0
000003|0
017880|2
017881|2
010689|3
010690|3
010692|3
002195|5
002196|5
002197|5
002198|5
002199|5
002200|5
002201|5
002202|5
Estructuración de los datos
Abrimos el archivo con una planilla de cálculo y disponemos los datos en tres columnas utilizando la función Texto en columnas. Los datos quedarán dispuestos del siguiente modo:
A partir de estos datos se procederá a realizar los recuentos. Para ello recomendamos utilizar la función de tablas dinámicas de la planilla de cálculo, o funciones como Contar.Si.
Los datos resultantes de los recuentos pueden compilarse en una tabla como la del siguiente ejemplo:
Minería de información
A modo ilustrativo incluimos un ejemplo de tabla completa que revela información sobre la distribución temática de la colección de libros impresos de la biblioteca seleccionada. Observamos claramente que la clase 5 es la que tiene mayor presencia en esta colección.
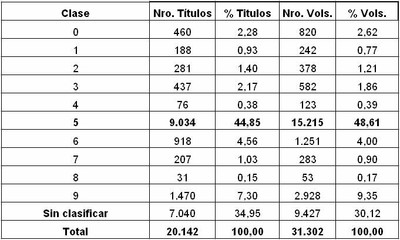
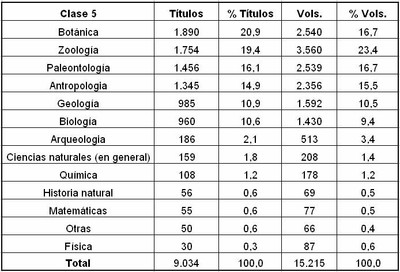
A partir de esta primera aproximación de la composición temática de la colección de libros y siguiendo el mismo procedimiento explicado precedentemente, pero adaptando las estrategias de búsqueda y campos seleccionados para la generación de los archivos de datos, la biblioteca puede realizar un análisis más profundo para cada una de las clases. En la siguiente tabla mostramos a modo ilustrativo la distribución temática de libros de la clase 5, utilizando el campo descriptores.
Nivel de actualización
Para determinar el nivel de actualización de la colección se calcula la edad a partir del análisis de las fechas de publicación. La edad de la colección permite conocer su antigüedad, definida como la cantidad de años que tiene un documento. Para determinar la antigüedad de la colección se utilizan ampliamente dos indicadores: vida media e índice de Price.
La Vida media es el tiempo o número de años en que la utilidad de una bibliografía se reduce al 50 %. Si se distribuyen los documentos por año de publicación, la vida media es la mediana de esa distribución. Este indicador fue introducido por Burton y Kebler (1960) para referirse al tiempo durante el cual fue publicada la mitad de la literatura corriente o la literatura referenciada dentro de una disciplina. Por extensión, puede aplicarse al estudio de la antigüedad de la colección de una biblioteca.
El Índice de Price es el porcentaje de documentos con una antigüedad de hasta 5 años. Este índice fue propuesto por Price (1970) para determinar cuán reciente es la bibliografía usada y cuál es la proporción de literatura clásica y corriente en una disciplina. Aplicado al estudio de la colección representa la relación entre los documentos de no más de 5 años de antigüedad y el total de documentos de la colección de la biblioteca (o del segmento estudiado).
Por regla general, los campos muy dinámicos suelen tener una Vida media baja y un Índice de Price alto. Por el contrario, en los campos con un índice de Price bajo y Vida media alta la documentación envejece más lentamente. Para el cálculo de estos indicadores recomendamos segmentar la colección por tipo documental y tema, en primer lugar, y por cualquier otro criterio que la biblioteca considere importante discriminar (por ejemplo, el caso de subcolecciones de libros raros, colecciones de particulares donadas a la biblioteca, etc.).
A modo de ejemplo explicamos a continuación el procedimiento para el cálculo de la antigüedad de la colección de libros de una temática específica (arqueología) de una biblioteca especializada en Ciencias naturales, mediante el cálculo de los indicadores de Vida media e Índice de Price.
Minería de datos
Desde el catálogo de libros de la biblioteca buscamos los registros que sean de la temática cuya antigüedad queremos calcular. Para el ejemplo: Arqueología. Asumimos que cada registro equivale a un título de libro, por lo tanto, cuando calculemos las frecuencias, estaremos contando cantidad de títulos de libros por año de publicación.
Para el subconjunto de registros recuperados (en nuestro caso 186) generamos un archivo de texto (*.txt) conteniendo el número de registro del catálogo (el MFN en bases de datos ISIS) y el año de publicación de los libros, separando ambos datos con el carácter pipe (|).
El archivo de texto adopta la siguiente forma, donde el dato que está a la izquierda de pipe corresponde al número de registro y el que está a la derecha el año de publicación.
000898|1956
001576|2008
001753|1919
001995|1977
002002|1967
002023|1978
002034|1946
002039|1987
002122|1984
002142|1969
002165|1958
002180|1929
002197|2005
002203|1966
002223|1969
Estructuración de los datos
Abrimos el archivo con una planilla de cálculo y disponemos los datos en dos columnas utilizando la función Texto en columnas. Los datos quedarán dispuestos del siguiente modo:
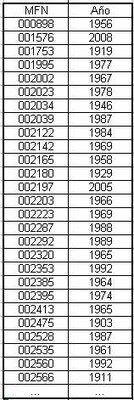
Hay que revisar los datos y verificar que todas las filas tengan el dato del año de publicación, y que los años estén normalizados.
Es esperable encontrar problemas derivados de la aplicación de las reglas de catalogación como las AACR2 para los casos de fechas desconocidas, o períodos de años. Casos del tipo: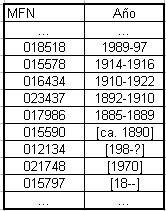
La biblioteca deberá determinar, en función de la cantidad de registros que presenten este problema si los deja fuera del análisis, o los transforma en datos cuantificables. En los casos de períodos de años una solución posible es calcular el año que representa el punto medio del intervalo. Así por ejemplo, para el período 1885-1889 adoptar el año 1887. En el caso de fechas dudosas como por ejemplo: [1970] una solución posible es quitar los corchetes y considerar ese año como válido. En nuestro ejemplo encontramos sólo 9 casos de 186 (5%), por lo que optamos por dejarlos fuera del análisis. Nos quedaron en total 177 registros.
Paso siguiente, ordenamos la tabla por la columna año, descendente.
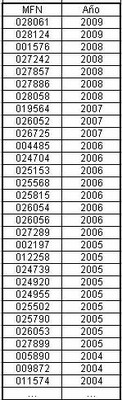
Realizamos el recuento de la cantidad de registros de cada año. Para ello aconsejamos utilizar la función de tablas dinámicas de la planilla de cálculo, o en su defecto alguna otra función para contar frecuencias como Contar.Si.
Como resultado obtenemos una tabla de frecuencias de años de publicación de los títulos de libros que ordenamos nuevamente en forma decreciente de años (desde el más nuevo que corresponde a 2009 en nuestro ejemplo hasta el más antiguo que es 1866). A continuación incluimos una muestra de la tabla resultante:
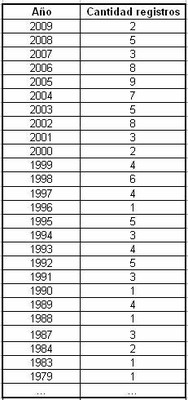
La tabla precedente tiene una columna de años que representan la fecha de publicación, ordenados en forma decreciente, y una columna de frecuencias (cantidad de registros del catálogo con esa fecha). A esta tabla debemos insertarle dos columnas más: una, con los años de antigüedad de los libros (si el año actual es 2010 correspondería a antigüedad 0; el año 2009 a antigüedad 1, el año 2008 a antigüedad 2 y así sucesivamente; otra columna, con el acumulado de frecuencias de cantidad de registros (acumulado de cantidad de registros).
Finalmente, la tabla completa quedará de la siguiente manera: 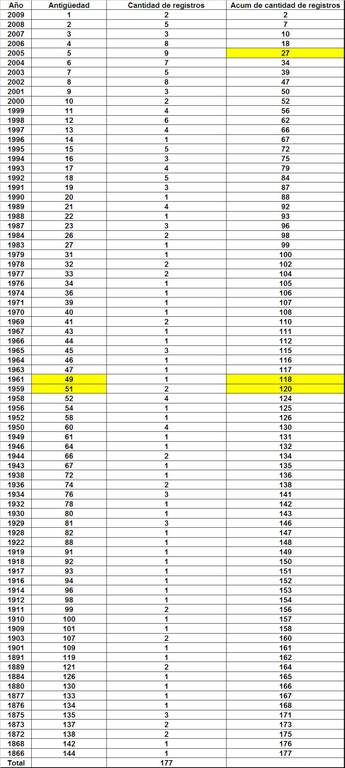
Descargar la tabla en formato csv
Con los datos de la tabla precedente ya podemos calcular los indicadores de Vida Media e Índice de Price. Como anticipamos, la vida media es la mediana de la distribución. Calculamos la mediana de la columna “Acum de cantidad de registros”. El valor es: 119. Como ese valor no está en la tabla, buscamos el número anterior y posterior: 118 y 120, que corresponden a una antigüedad de entre 49 y 51 años (columna Antigüedad). Para ser más precisos podemos calcular la media de ambos (sumar ambos valores y dividir por dos), lo que da exactamente una antigüedad de 50 años.
Para calcular el índice de Price debemos obtener el porcentaje de documentos con hasta cinco años de antigüedad. En la columna “Acum de cantidad de registros” la frecuencia que corresponde a los cinco años de antigüedad es 27. Entonces: 27 / 177 * 100 = 15 %, que es el valor del índice de Price.
Minería de información
¿Cómo interpretar estos indicadores? ¿Qué nos dicen sobre la colección?
Como ya anticipamos previamente, una vida media alta y un bajo índice de Price representa a disciplinas cuya literatura envejece lentamente. Este es el caso de la Arqueología y este rasgo es el que refleja en la colección de libros de la biblioteca del ejemplo. Por lo que a la hora de tomar decisiones sobre la colección de esta temática en lo que hace a la antigüedad sabemos que los libros con hasta 50 años desde su fecha de publicación siguen siendo de utilidad para los usuarios de ese campo temático.
Otros aspectos
Como ya hemos mencionado, los aspectos seleccionados para los ejemplos precedentes son sólo ejemplos. Se pueden realizar evaluaciones que involucren todas las características de la colección que la biblioteca considere pertinentes. Así por ejemplo una biblioteca podría requerir evaluar la procedencia geográfica de los documentos y seleccionar la variable país de edición de los diferentes tipos documentales; la modalidad de adquisición (compra, canje o donación), los tipos de editoriales (comerciales, académicas, de organizaciones profesionales), la movilidad (abiertas y cerradas para el caso de las publicaciones periódicas), el factor de impacto u otras medidas relacionadas con la influencia de las revistas, etc.
Para el caso particular de las publicaciones periódicas, se pueden plantear estudios de la calidad de la colección basados en parámetros cualitativos como los que proponen:
- ICSU http://www.icsu.org/index.php4,
- Latindex http://www.latindex.unam.mx/
- Redalyc http://redalyc.uaemex.mx/
- ISI http://science.thomsonreuters.com/
También se pueden plantear estudios cuantitativos basados en análisis de citación como los que ofrecen los siguientes portales:
- SCImago Journal et Country Rank http://www.scimagojr.com/
- In-Recs http://ec3.ugr.es/in-recs/
Ver un ejemplo aplicado a la evaluación de colección de revistas en el Contenido relacionado Estudio de la hemeroteca de BIBHUMA año 2006.
Problemas frecuentes: Falta de datos o datos no normalizados
Uno de los principales problemas que se presentan a la hora de realizar estas evaluaciones de exploración y diagnóstico de la colección radica en la falta de normalización que presentan los datos, y en algunos casos en la carencia de ellos. En este sentido una rutina que puede ponerse en práctica antes de la recolección de los datos consiste en hacer un sondeo de la presencia y ausencia de los campos en la fuente de datos que se va a utilizar, y por otro lado una exploración de las variantes de las formas de las entradas de tipos documentales, soportes, idiomas, años de publicación y muy especialmente de la clasificación temática en lenguaje natural (encabezamientos de materia o descriptores), que son las que más problemas de normalización presentan.
La detección de la ausencia de datos o la presencia de datos mal cargados debería dar lugar al desarrollo de procedimientos de control que garanticen la eliminación de estos problemas en el futuro, o al menos que contribuyan a reducir la probabilidad del error. Muchos de estos problemas se resolverían a través de sistemas informáticos que tengan incorporados mecanismos de validación de datos y control de autoridades.